-01.png?width=926&height=181&name=Netgate%20Logo%20PMS%20(horizontal)-01.png "Netgate Main Logo")
%201.png?width=302&name=Netgate%20Logo%20PMS%20(horizontal)%201.png "NetgateColorLogoRegisteredRGB.png")
Packet Processing Explained
First, a few basics. Internet traffic largely breaks down to either files or commands. Files could be a pdf, spreadsheet, image, movie, etc. Commands are instructions to do something - typically managed by interaction through a browser or client with an application somewhere. It’s, of course, much more complicated than that, but for our purposes this will suffice.

Now commands and files have to be sent back and forth between your device and the far end server supporting your application with streams of Internet Protocol (IP) packets, each with its own header and payload. As you are likely aware, there are any number of network and/or security policies applied to each packet’s header and/or payload along its journey to make sure it is 1) delivered along the most efficient path, 2) adherent to the rules of its transmission protocol, and 3) hopefully protected from harm or misuse.
IP Packet Journey

Ok, probably for anyone reading this primer, that much is understood. But, repeating the basics serves a purpose. It gives us a baseline for discussing what is more important - and that is how IP packets are processed.
Vector Packet Processing
What if packet processing could be freed from the constraints of the kernel? What if the data cache could be applied to an array of packets simultaneously, instead of one at a time?
It’s no longer a ‘what if’. It’s a reality. Introducing Vector Packet Processing (VPP). VPP is an open source version of Cisco’s Vector Packet Processing technology - which is central to over $1 billion of Cisco ASA and CSR products. So, the core technology is proven. In essence, VPP is a modular packet processing node graph abstraction, where each node processes a vector of packets to reduce CPU I-cache thrashing, and is made extensible and dynamically reconfigurable via plugins. Let’s break that down a bit.
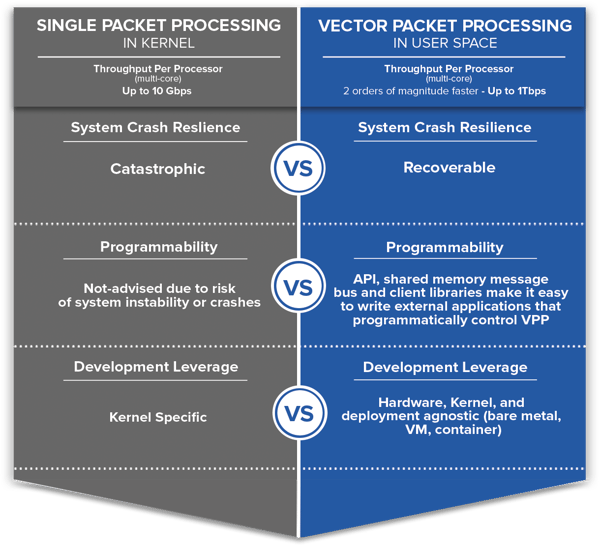
VPP moves the packet processing workload out of kernel space and into user space. User space is where programs and libraries (that the OS uses to interact with the kernel, e.g., software that performs input/output, manipulates file system objects, application software, etc.) reside. As a result, there is much more ‘elbow room’ to manage cache-based instruction sets.
It then processes that vector of packets through a packet processing graph:
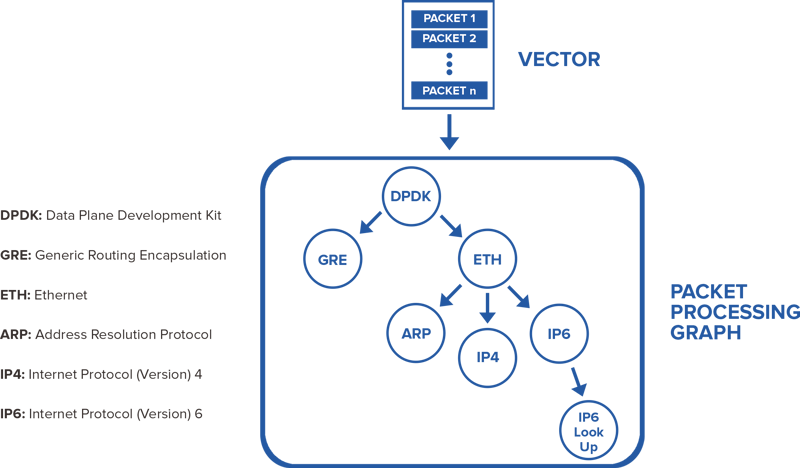
Here is the key performance breakthrough. Rather than processing each packet through the entire processing graph, and then fetching the second packet and processing it through the entire graph, VPP fully processes the vector of packets through the first graph node before moving on to the next graph node. The first packet in the vector ‘warms up’ the instruction cache, so remaining packets can be processed extremely fast - sharply reducing the cost of processing each subsequent packet in the vector. This leads to 1) very high performance for processing a single packet, and 2) statistically reliable performance in processing a large number of packets over time. Additionally, VPP will often prefetch what it knows to be the next packet(s), ensuring that the CPU doesn't stall while the next packet is fetched from RAM. As a result, throughput is high and latency is consistently low.
Let’s go back to our performance example above - where we explained a number of systems will be required to fill a 10 Gbps pipe with 64-byte packets using kernel processing. And since 10 Gbps is relatively pedestrian these days, let’s kick it up a notch. Suppose you need 100 Gbps networking. VPP makes that achievable in software. 100 Gbps is a 10X jump over 10 Gbps, so we now need to process between 8 and 148 Mpps - depending on packet frame size. If the packet frames are large, we can forward 100Gbps - on a single core. If packets are tiny, we can process 100 Gbps on 10 cores. Normal internet traffic is a mix, so we’ll practically land somewhere in between. Either way, this leads to a dramatic reduction in CapEx and OpEx relative to kernel processing.
 While VPP makes software-based packet processing extremely attractive, there are still times when hardware acceleration is appropriate. Fortunately, the graph node architecture allows hardware acceleration to be easily inserted. As an example, computationally intensive traffic processing applications like hardware cryptographic acceleration - which helps offload the performance demands of securing and routing Internet traffic - can appear as just another graph node.
While VPP makes software-based packet processing extremely attractive, there are still times when hardware acceleration is appropriate. Fortunately, the graph node architecture allows hardware acceleration to be easily inserted. As an example, computationally intensive traffic processing applications like hardware cryptographic acceleration - which helps offload the performance demands of securing and routing Internet traffic - can appear as just another graph node.
Deployment
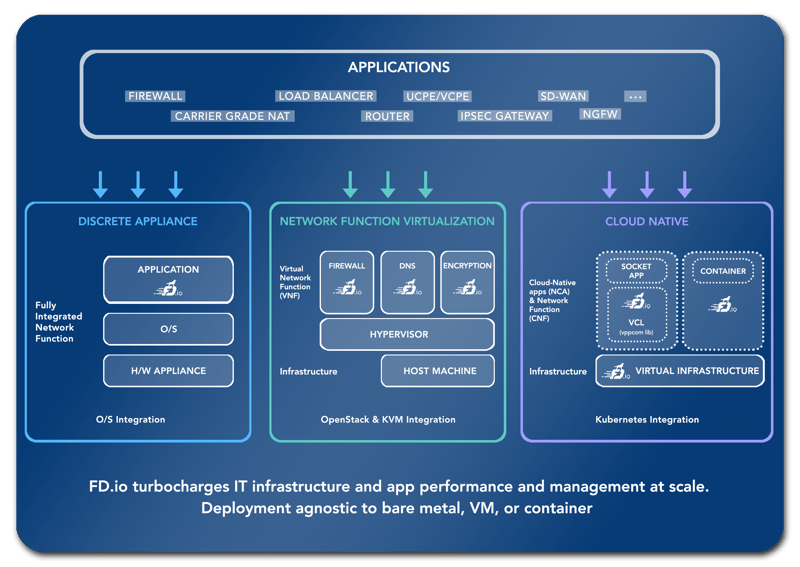
FD.io is a collection of projects and libraries chartered to enable flexible, programmable and composable services on generic hardware platforms. VPP, of course, figures prominently into the mix. It runs in user space on multiple architectures including x86, ARM, and PowerPC architectures on both x86 servers and embedded devices.
As shown in the diagram below, VPP (represented in each of the three deployment models by the FD.io logo) is truly hardware, kernel, and deployment (bare metal, VM, container) agnostic:
Productization
VPP is the wave of the future for all secure networking packet processing needs. Its packet processing power, programmability, manageability, and deployment flexibility make it essential for consideration by any organization looking for secure networking performance and scale. But VPP is an open source project, not a product. Open source projects have the advantage of community-driven development creativity and time-to-market. But development projects must still be productized in order to meet the demands of real-world deployment. That requires rigorous software integration, testing, packaging, distribution, and support. The expertise, investment, and effort required to effectively productize an open source project - let alone one experiencing rapid advancements - is not for the faint of heart. Productizing open source secure networking projects into enterprise and service-provider-ready solutions is Netgate’s expertise. And TNSR® software is the answer to VPP productization.
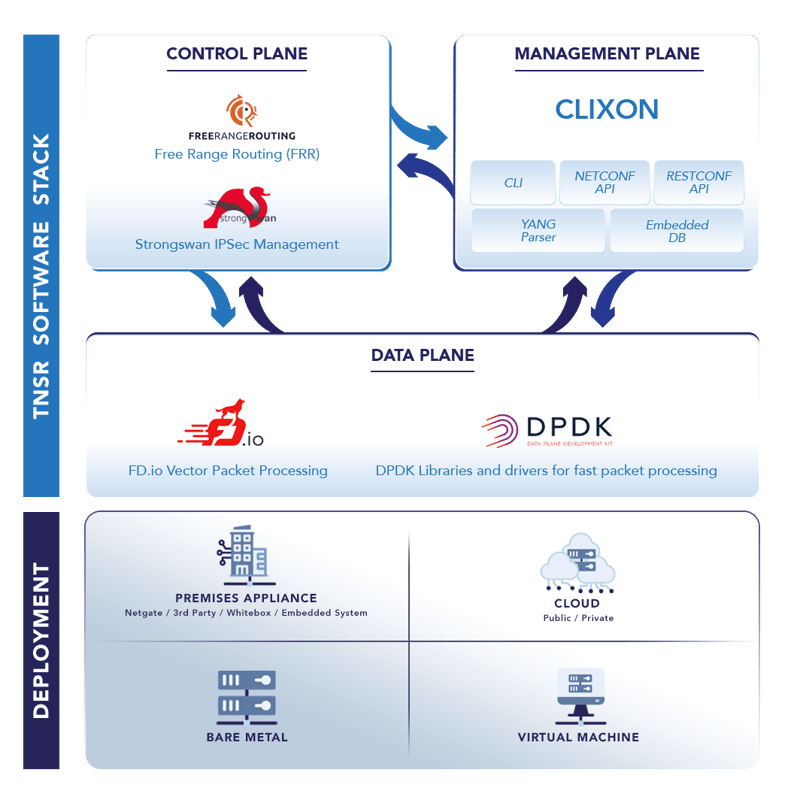
Netgate's TNSR router leverages the power and performance of Vector Packet Processing (VPP)
Whether in the data center, on premises, or in the cloud, TNSR offers advanced high performance routing and VPN capabilities for enterprises, service providers, and government organizations, at an unbeatable Total Cost of Ownership.
